

Introduction
When a program runs, values are created, modified and destroyed in some cases. Our system needs a medium that can both hold the data and access the data very quickly while the program is running. Another important part of our system is responsible for how fast our programs can run. Because there are many ways to write a program, we can optimize our code to help the computer do work faster, without having to upgrade any physical components of the system.
You can imagine a piece of memory like a bunch of little squares. Each square holds a “byte” of information.
[ ][ ][ ][ ][ ]
[ ][ ][ ][ ][ ]
[ ][ ][ ][ ][ ]
But computers today have many more bytes than the small example above. A 4gb memory stick holds 4 billion bytes. That is a lot of data! Memory is also known as RAM which stands for Random Access Memory. Without getting too technical RAM works with data while the computer is powered on, and is very fast at accessing data, however once the power is off the data is lost. Any data that needs to be stored long term is moved to a computers hard drive, where data is stored with or without power.
Using C arrays and storing strings
In the C programming language we abstract out the idea of memory and use a data type known as an array. Let’s store my name in an array:
#include <stdio.h>
int main (void) {
char name[] = "John"; // initialize an array of type char
int length = sizeof name / sizeof name[0];
for (int i = 0, l = length; i < length; i++)
printf("%c", name[i]);
printf("\n");
}
Let’s store some numbers:
#include <stdio.h>
int main (void) {
int numbers[8] = {1,2,3,4,5,6,7}; // initialize an array of type int and size 8
numbers[7] = 8; // adding the final int to the array
int length = sizeof numbers / sizeof numbers[0];
for (int i = 0, l = length; i < length; i++)
printf("%i", numbers[i]);
printf("\n");
}
Arrays can hold any data type, and can be initialized in different ways. As shown above, we can declare an array and leave out a number between the brackets, such as “name[]” and then give it a value like “John.” Now the name array is of size 4.
Alternatively we can declare the array with a size between the brackets. When I created the numbers array I first declared it “numbers[8].” You can see elements of the array are added using “{ }” curly braces. It’s important to note you can only use the curly brace notation at the time you declaring the array, or better said when you instantiate the array. Once it has been instantiated, you can only add items one at a time, which I demonstrated by adding the final number to our numbers array:
"numbers[7] = 8; // adding the final int to the array"
Null Terminator and Garbage Values
In C you can access pieces of memory beyond what you have initialized. What does that mean? Let’s demonstrate:
#include <stdio.h>
int main (void) {
int numbers[4] = {1, 2, 3, 4};
int length = sizeof numbers / sizeof numbers[0];
int explore = length + 5;
for (int i = 0, l = explore; i < explore; i++)
printf(" [%i] ", numbers[i]);
printf("\n");
}
The output in the C repl is this:
[1] [2] [3] [4] [4195840] [0] [4195408] [9] [9]
We know the array holds 4 spots in memory for our numbers 1 through 4. But the “explore” variable goes beyond the length of our array, so when we loop we are pulling values up to a length of 9 ( or put another way we are going up to the 8th element since it is zero indexed).
In my case those mystery values were “[1] [2] [3] [4] [4195840] [0] [4195408] [9] [9] .”
If you were to run this on your system you would most likely get completely different numbers.
So can we change those mystery values?
#include <stdio.h>
int main (void) {
int numbers[4] = {1, 2, 3, 4};
int length = sizeof numbers / sizeof numbers[0];
int explore = length + 5;
for (int i = 0, l = explore; i < explore; i++)
printf(" [%i] ", numbers[i]);
printf("\n\n");
printf("changing a value i'm not supposed to be changing!\n\n");
numbers[4] = 42;
for (int i = 0, l = explore; i < explore; i++)
printf(" [%i] ", numbers[i]);
printf("\n\n");
}
YES! YIKES!
We could totally blow up our system, accidentally changing an important value. Maybe that space in memory was a boolean set to false so someone had to enter a password to access the program. By setting it to some number we are switching it to true and now everyone can bypass our authentication! Perhaps not the best example but hopefully gets the message across, which is be careful because there is nothing guarding you from this except your own code!
So when dealing with strings, C uses a special character called the null terminator it works like this:
#include <stdio.h>
int main(void){
char name[100];
printf("name:");
scanf("%s", &name);
char t = '#include <stdio.h>
int main(void){
char name[100];
printf("name:");
scanf("%s", &name);
char t = '\0'; // null terminator character
printf("Hello ");
for(int i = 0; name[i] != t; i++)
printf("%c", name[i]);
printf("!\n");
}'; // null terminator character
printf("Hello ");
for(int i = 0; name[i] != t; i++)
printf("%c", name[i]);
printf("!\n");
}
C automatically puts a ‘\0’ character at the end of our array of characters so we know when to stop if the length of the array is unknown.
We have an array of length 100 but the name of the user is unknown, so we have to loop until we hit the null terminator:
[J,O,H,N,\0,……….]
So once we hit that terminator we know when to stop which saves us from hitting garbage values we aren’t supposed to access!
Remember we need space in our array for the null terminator.
Searching
Whenever we create a strategy on how to solve a problem, we create steps that eventually lead to the problem being solved. This is what is called an algorithm, and when it comes to searching for information in a data set, there are several algorithms available for us to use. Let’s say we have a set of numbers within an array:
[1,50,24,99,12,4]
Now let’s take a brute force approach to searching. This involves looking at each element and checking it against the value we’re looking for:
given an array of numbers and a value to find loop through each number if the current number is the value to find return that value back.
In our case we’re using brute force because the numbers are not sorted. Now take this array of integers:
[1,5,6,8,9,15,25]
How can we search faster if the array is sorted? We can search faster using binary search, because we can jump to the mid point and remove half the array depending on our value being less than or greater than the mid point value:
Binary search given a target and a sorted array find the midpoint of the current array if midpoint value is target return decide which half holds the target value repeat the steps with the subarray to the right or left of the current midpoint Once there are no more halves return the value or FALSE if not found
Sorting
Several sorting algorithms exist. In the lecture David talks about selection sort, bubble sort, and insertion sort. Each one uses a different strategy to sort an array.
- selection sort goes through each element, finds the smallest and moves it to the beginning of the array.
- bubble sort looks at the current element and the next element, we’ll call a pair, and compares each pair in the list. If the pair is out of order, it swaps them. It passes through the array over and over until the list is sorted.
- insertion sort at first seems similar to selection sort but is a little different. It goes through the list comparing each element with the first element. If it finds an element smaller than the first element it moves it to the beginning of the list. This is different from selection sort because it is not trying to find the smallest list in the entire array, only in comparison to the first element.
Asymptotic Notation
How do we measure the efficiency of our algorithms? Asymptotic notation is a language to describe how are algorithms behave given an input. Let’s call our input f and our array of elements n. We “run” our function so to speak just like in a C program f(n) which would be called “f of n.”
This gets super confusing for me very quickly so here are the main points. There are three terms commonly used:
- Big O – describes how our algorithm behaves in the worst case run time (worst meaning, in the case of sorting, our array is completely out of order so the algorithm does a lot of swapping, checking etc). This is also called the asymptotic upper bound.
- Big Omega – describes the best case run time (least amount of swapping checking, in our case given an already sorted list what does our algorithm have to accomplish to prove it is sorted). This is called the asymptotic lower bound.
- Theta – no “Big” here, Theta describes an algorithm with an identical upper and lower bound. This is also called the asymptotically tight bound.
Here is a graph showing how algorithms can potentially behave depending on the input size:
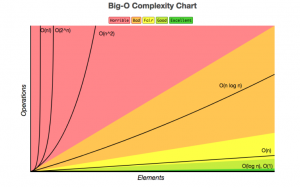

Common run times are
- O(n) big O of n you might hear
- O(n²) big O of n squared
- O(log n)
- O(n log n)
Constant time is described as 0(1). This is the fastest possible runtime.
So let’s compare the upper bounds of each sorting algorithm we’ve described so far:
| Algorithm | Big O (Worst Case) | Big Omega (Best Case) |
| Bubble sort | O(N2) | O(N) |
| Selection sort | O(N2) | O(N2) |
| Insertion sort | O(N2) | O(N) |
Merge Sort / Recursion
Merge sort has it’s own section because in order to implement this algorithm in C, we need to use recursion, which allows a function to call itself. Let’s look at a bad example of recursion first, then fix it using a base case.
DO NOT RUN THIS CODE (INFINITE LOOP)
#include <stdio.h>
void bad_recursion();
int main(void)
{
bad_recursion();
return 0;
}
void bad_recursion()
{
bad_recursion();
}
Now let’s add a condition that when met returns. It could return a value but in our case we’re using the return and giving back nothing (void).
#include <stdio.h>
void good_recursion(int base_case);
int main(void)
{
good_recursion(5);
return 0;
}
void good_recursion(int base_case)
{
if (base_case == 0)
return;
printf("currently at base_case# %i\n", base_case);
good_recursion(--base_case);
}
Running our good_recursion function prints:
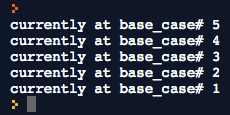
We’ll go deeper as to how this works, but for now just remember recursion is similar to a loop but reads more elegantly, and a base case is required, so the function can return at some point instead of getting caught in an infinite loop.
Now that you’ve been exposed to recursion, let’s get into merge sort. First a visual to demonstrate what merge sort is doing differently compared to the other sorting algorithms I’ve mentioned previously.
Let’s look at some pseudo code
Given a list if list is of size 1 or 0 return. Otherwise split the list in half run merge-sort on each half merge the halves together
Comical as it is, this brings a powerful side effect, which is merge sort has a run time of O(n log n). If you reference the chart I added earlier, this is much faster than anything we’ve come across before. By dividing the problem over and over, even if our data set doubles, merge sort only adds 1 step!
Also again notice the base case in our pseudo code. When we run merge sort in C, we use recursion, this means we need to return at some point so the work isn’t passed infinitely. Think of each function call being placed on top of each other, like water balloons tightly packed in a vertical pipe. Once the base case is met imagine each balloon popping starting from the top balloon:
|O|
|O|
|O|
Remember the first time our function gets called is the balloon at the bottom. This arrangement is known as FILO or First In Last Out. When the top balloon pops it “returns” water down to the previous function, which then pops, returning down once again. Other articles talk about returning back “up” to the main function, but then show a visual of functions on a stack vertically that return going down. Programmers like to make things confusing don’t they?
Merge sort can be difficult to understand because it doesn’t return anything back but passes work to other recursive versions of itself. If this makes no sense don’t worry. I spent 3 weeks before I was able to write it from scratch with no reference. In a later article we’re going to really go deep with some simple examples.
Conclusion
We are also briefly told in this lecture our problem set involves helper functions that will generate music using text files!
Hi,
This comment is from Scott from the Hudson Valley Programmers Meetup.
You may already know about this site that I shall mention. If you liked the clean code book, you will probably like this:
Cleancoders.com
Hey Scott!
Thanks for your comment and taking a look at the website. I just went on the cleancoders.com site and was really impressed with the content on the homepage. Looking forward to having some free time to explore more. See you at the next meetup I hope!
Hi Johnny. Are you still working on the CS50 course? I got lost very quickly, but i have to say your posts going over the lectures and shorts and such has really helped me grasp things a little more. I wonder where you’re at now with coding and if you’re still doing CS50?
Hi Jesse,
Funny you should ask as I am just finishing up some code on my github gists page for another article. After completing my first triathlon I took a break and have been focusing on my new job. I will be writing about all these life changes after I finish my week 2 shorts and walkthrough articles. Sorting algorithms really really challenged me haha. I am looking forward to posting my thought process and continuing CS50 all the way to the end. Thanks for your support it means a lot!