

Computational Complexity
How quickly computers run tasks depends on two factors, generally:
- Physical Resources
- Source code optimization
Let’s take a $5,000 computer, and imagine we run a simple “hello world!” program. An expensive computer can handle it, but so can a cheaper $200 laptop. Run that same program inside a while loop with a condition value of TRUE, and both systems will hang (an infinite loop). Hardware can help a system run faster, but our program’s algorithms also play an important role.
How do we measure performance of an algorithm under the load of more data?
How do we measure how long would it take to sort 10 names, or 10 million names?
the answer is Big O notation, also called asymptotic notation, time complexity, or space complexity.
Big O notation is usually expressed as the worst case run time of an algorithm.
We look at the worst case because it helps us understand the minimum amount of resources required to run our program.
The fastest runtime is known as O(1) or “big O of 1.” This means our algorithm only requires one step to run regardless of the output. Here is a silly example:
int myfunction(int* myarray)
{
return 42;
}
In the worst case (and best case) , myfunction only runs 1 step.
Let’s look at another function and describe it in Big O notation:
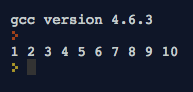
The code above has a for loop that executes the printf statement 10 times. The array has the number 42 added at the end, which is what the function is using as a condition to stop the loop.
My algorithm is named function and gets called on line 15.
So if the number of items in our program could be expressed as just n, and function, which is a function could be expressed as just f, this can be expressed as f(n).
so this function calls my array of numbers and runs printf for each number in the array.
10 numbers? Runs 10 times or n = 10 so f(10)
100 numbers? Runs 100 times or n = 10 so f(100)
and back to just abstracting it all back out to f(n).
So in the worst case our algorithm runs in Big O(n).
In the best case it will also run in Omega(n).
When an algorithm has the same best and worst case within the parenthesis we say it runs in Theta(n).
So in plain english, every piece of code you write takes a certain amount of steps, and there is a mathematical way to show how your code runs.
From Wikipedia:
let f(x) = 6x4 − 2x3 + 5, and suppose we wish to simplify this function, using O notation, to describe its growth rate as x approaches infinity. This function is the sum of three terms: 6x4, −2x3, and 5. Of these three terms, the one with the highest growth rate is the one with the largest exponent as a function of x, namely 6x4. Now one may apply the second rule: 6x4 is a product of 6 and x4 in which the first factor does not depend on x. Omitting this factor results in the simplified form x4. Thus, we say that f(x) is a “big-oh” of (x4).
wikipedia – https://en.wikipedia.org/wiki/Big_O_notation
Log n
Algorithms that run in O(log n) or O(n log n) might be confusing if you’ve never encountered the log function in mathematics. If you’ve ever seen something like this:
26 = 64
you know we’re looking at “2 to the power of 6 is equal to 64.”
The little 6 is the exponent, and the 2 is the base.
When we log something we get kind of the opposite of what an exponent gives us. It gives us the exponent we would need to get to that number. Take this for example:
log2 64 = 6
So now that little number is 2, which in this case is still the base number. So we would say “log base 2 of 64 is 6,” or in other words:
If you had the number 2 as your base, and you wanted to get to the number 64 using an exponent, you’d need the little number 6. This would bring us back to: 26
Any algorithm that is log n uses a divide and conquer strategy. This means we split the input data in half, over and over until we get the value we’re looking for. An algorithm like binary search runs in log n. Also in most cases, when we talk about log n we are implying log2 which is base 2. Again we are dividing in half, which is by 2:
log2 8 = 3 log2 16 = 4 log2 32 = 5 // notice how the input size doubles but our result is only 1 // more step! If this was O(n) it would be 32 = 32 steps!
Try out these resources to learn more:
A Log base 2 calculator to play around with
(If all of this was confusing, or if you know how to explain this better please leave a comment!)
Watch how it compares to a linear or sequential search algorithm:
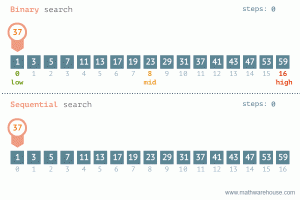
Binary search is only possible when our list is sorted, which brings us to our next example n log n, which is a runtime commonly associated with sorting.
Merge sort runs in n log n because it has to touch each element it’s given, thats the first n, and the log n is the divide and conquer part where it splits the array over and over until finally recombining them back together.
n log n is not as efficient as log n when we’re purely talking about runtime, however in the case of sorting, n log n is very efficient when compared to other sorting algorithm run-times.
Selection Sort
After watching each short, I decided to try and implement all the sorting algorithms in C. I’ll show the code and briefly go over the parts that were confusing and how it finally clicked for me:
I’m probably going to say this a few times, but understanding the correct bounds of a loop always confuses me. Don’t be afraid to use printf here and watch what is happening in the console. You can also use GDB in the CS50 IDE and watch how a variable changes each time to make sure you’re in the place you expected to be in the loop.
One example of this is on lines 20 and 24. The outer loop has a condition i < len-1 and the inner loop has i < len. This is because the outer loop has to stop 1 element short. Why? Because since it is comparing with other elements in the list there has to be at least 1 element to compare in front! So notice the inner loop starts with j = i+1, which in english means “start in front of i because we have to compare to check if something up ahead is smaller so we can swap. If i moved all the way to the end, then j would be beyond the list, some value in memory we are not supposed to be accessing!
Starting on line 24 you can see the nested for loop. This is why selection sort runs in Theta(n²). Best or worst case you will always have the nested loop, so for n elements in one loop the inner one also runs n times. For more info on the math involved you can check out Khan academy’s article on selection sort.
Bubble Sort
Using a do while loop made sense for this one. Because bubble sort will take several passes on the array, we can have a variable keep track of how many swaps took place. Line 19 shows swap initialized to zero. Now the for loop inside our do while section will keep doing the bubble sort swaps over and over until no swaps occur, or in our case if sort_counter > 0 on line 30.
Insertion Sort
Notice how our for loop on line 22 has i equal to 1 from the start. We need something to sort behind the current element. This way when we create j, and use it to sweep through all the values before the current, we have at least 1 element from the start which is j-1. Also remember we are iterating in the while loop from the current element backwards so decrement j don’t increment. If the current element is in position 5, then j is going 4,3,2,1,0 before breaking out of the while loop.
Linear Search
Hopefully the process of creating the array of numbers and getting the length is becoming more automatic. We initialize the array variable with an array, and don’t forget to add the [ ] symbols or expect a whacky error. So we want:
int array[] = {1,2,3,4,5,6,7,8,9,10};
once we have our array we need a target that we’re looking for. In the code sample above it’s 10.
In our for loop we’ll have the usual i running through each element in our array. We want to keep track of array[i] so we can reference the position or place in our array where we found the matching value.
Here is an alternative way to implement linear search using a while loop:
The next half of these shorts gets into some more complex strategies, which although are more efficient, are a little frustrating to wrap your head around. I will do my best to share how I dealt with these concepts and include some code examples. Until next time!
On a personal note:
I have not published anything in a quite some time, and hope to get back on track with posting more frequently.
In May I finished my first Triathlon event, and I also started a new job working the IT service desk at Vassar College. These new events in my life have given me a great deal of pride! I am also fortunate that my new job has me in the presence of work/study Vassar students, some currently computer science majors!
I appreciate the comments people have left and the support of the Hudson Valley Programers meet up, it has really kept me motivated!